
Streamlining Data Flows: Using DBT to Transform Salesforce Data with Reverse ETL
Crafting the Best Open-Source Guide for Data Practitioners


Introduction
After attending two of the largest data conferences this year, I felt compelled to share my experience with reverse ETL—particularly when it comes to using open-source tools. At one event, I spoke with someone building a paid product around reverse ETL, and they were intrigued by how I tackled the challenge of integrating Salesforce with our datastores. At another, a major company shared their struggles with some well-known reverse ETL tools and the broader challenges they were facing. This inspired me to create a comprehensive, open-source guide for data engineers who don’t have access to the latest premium tools. In this article, I’ll walk you through how I extended the Airflow SalesforceBulkOperator, combined it with DBT, and addressed key considerations—like how to end to end verify your pipeline is running —for a scalable reverse ETL solution.
Reverse ETL is the process of moving data from a data warehouse or data lake back into operational systems such as your business applications or your CRM (like Salesforce). Unlike traditional ETL, where data is taken from your source system, transformed, and then loaded into your data warehouse, reverse ETL takes the insights generated in your warehouse analytics and sends them out to downstream tools. This enables teams like sales, marketing, and customer support to take action based on your latest data.
Creating the Custom Operator
The standard Airflow SalesforceBulkOperator is nearly sufficient for most users' needs. The existing operator is designed to use the Salesforce Bulk API to load large batches of data into the platform. The default connection type and operator already function effectively for loading data into Salesforce. However, I encountered a challenge when attempting to pass data from a database, particularly when running a DBT model and wanting to integrate that output with the existing operator. To address this, I opted to use the SqlHook to directly feed the output into the payload argument of the existing operator. By creating this subclass, we enhance its functionality without reinventing the wheel, providing a standardized interface for loading data into the existing implementation.
In simple terms, there's already a tool that loads data into Salesforce that is open source and a part of Airflow. I've enhanced it to connect with any SQL database, allowing DBT to handle the data transformations. With this extended operator, you can now send the transformed data directly from your database into Salesforce.
from airflow.providers.salesforce.operators.bulk import SalesforceBulkOperator
from airflow.providers.common.sql.hooks.sql_hook import SqlHook
class SalesforceBulkSQLOperator(SalesforceBulkOperator):
"""
Executes a SQL query and inserts the results into Salesforce using bulk operations.
Columns in the SQL query are expected to match 1:1 to their corresponding API fields in Salesforce.
Args:
sql_conn_id: The ID of the SQL connection to use.
sql: The SQL query to execute.
object_name: The name of the Salesforce object to insert into.
external_id_field: The name of the external ID field in the Salesforce object.
batch_size: The number of records to include in each batch.
use_serial: Whether to use serial mode for the bulk operation.
skip_if_empty: If True, skip execution and log if no records are found. If False, raise an error when no records are found.
**kwargs: Additional arguments passed to the parent BaseOperator.
"""
def __init__(
self,
sql_conn_id: str,
sql: str,
object_name: str,
external_id_field: str,
batch_size: int = 10000,
use_serial: bool = False,
skip_if_empty: bool = True,
**kwargs,
):
super().__init__(**kwargs)
self.sql_conn_id = sql_conn_id
self.sql = sql
self.object_name = object_name
self.external_id_field = external_id_field
self.batch_size = batch_size
self.use_serial = use_serial
self.skip_if_empty = skip_if_empty
def execute(self, context):
# Get SQL hook and execute query
sql_hook = SqlHook(self.sql_conn_id)
records = sql_hook.get_records(self.sql)
# Create payload from query results, mapping fields by name
payload = []
for row in records:
record = {}
for column, value in zip(self.sql.split(','), row):
record[column.strip()] = value
payload.append(record)
# Check if records exist
if not payload:
if self.skip_if_empty:
self.log.info("No records found in the SQL query. Salesforce bulk insert will not be executed.")
return # Exit gracefully if no records are found
else:
error_message = "No records found in the SQL query, but skip_if_empty is set to False. Raising an error."
self.log.error(error_message)
raise ValueError(error_message) # Raise an error if skip_if_empty is False
self.log.info(f"Preparing to insert {len(payload)} records into Salesforce {self.object_name}.")
# Execute Salesforce bulk insert
bulk_operator = SalesforceBulkOperator(
task_id=self.task_id, # Can be omitted
operation="insert",
object_name=self.object_name,
payload=payload,
external_id_field=self.external_id_field,
batch_size=self.batch_size,
use_serial=self.use_serial,
)
# Error handling during bulk operation
try:
bulk_operator.execute(context)
self.log.info(f"Successfully inserted {len(payload)} records into Salesforce {self.object_name}.")
except Exception as e:
self.log.error(f"Salesforce bulk insert failed: {e}")
raiseWith this operator, you can connect to any SQL-compatible database. This effectively decouples the final solution from DBT, which I believe is a best practice. It enables Airflow to seamlessly connect to any SQL database and transfer data to Salesforce.
Understanding Reverse ETL
To begin, let’s discuss how to effectively match records in Salesforce. A crucial aspect of creating a seamless data flow is recognizing that you often need to extract data from Salesforce to complete the process. This is where open-source connectors like Airbyte, Singer, and others come into play. These connectors excel at facilitating data extraction, but the critical point to remember is that you need data from Salesforce to calculate the deltas—differences between datasets—which you'll subsequently use to build your DBT models.
It's important to clarify that this article will not delve into the specifics of writing a DBT model. However, it’s essential to understand that DBT acts as the engine that transforms the data within your data warehouse, enabling you to generate insights and reports efficiently. How you incorporate this transformation into your DAG is flexible and can be tailored to your workflow. Once you have transformed the data as needed, you can call the bulk operator to facilitate the loading process.
While we won't cover the intricacies of writing deduplication logic in this article, we will discuss the importance of conforming the expected columns to ensure they match the 1:1 structure that Salesforce requires. This step is vital for successful data uploads, as it minimizes the risk of errors and maximizes the efficiency of your integration.
Data Flow and Operations in Salesforce
The flow of data—from and to Salesforce—is essential depending on what you're trying to achieve. With the Salesforce Bulk API, there are four main operations you can perform: Insert, Update, Delete, and Upsert.
Insert: This is where deduplication is critical. You don’t want to create duplicate records by inserting data that already exists in Salesforce. By joining your new data with existing Salesforce data, you can deduplicate before sending the data to Salesforce.
Update and Delete: These operations require the Salesforce record’s unique ID. Without it, Salesforce won’t know which record to update or delete. Ensuring you have this ID is vital for these processes and why it is vital to have the sync from Salesforce.
Upsert: Upsert allows you to insert or update records based on an external ID field. For example, if you have a unique identifier from another system (like account_id from System X), and it’s marked as an external ID in Salesforce, you can use it to perform upserts. However, be aware that if there are duplicate external IDs, Salesforce can struggle to handle them and may silently fail—which I’ll explain more later.
Authentication is fairly straight forward, and they do a great job explaining how to do it here in the bulk api documentation.
Navigating Salesforce Fields
Let’s dive into Salesforce fields. There are a few ways to identify the fields you need, but for this article, I’ll walk you through one method. First, go to the Object Manager in Salesforce. Then, navigate to the object you’re working with and click on Fields and Relationships.
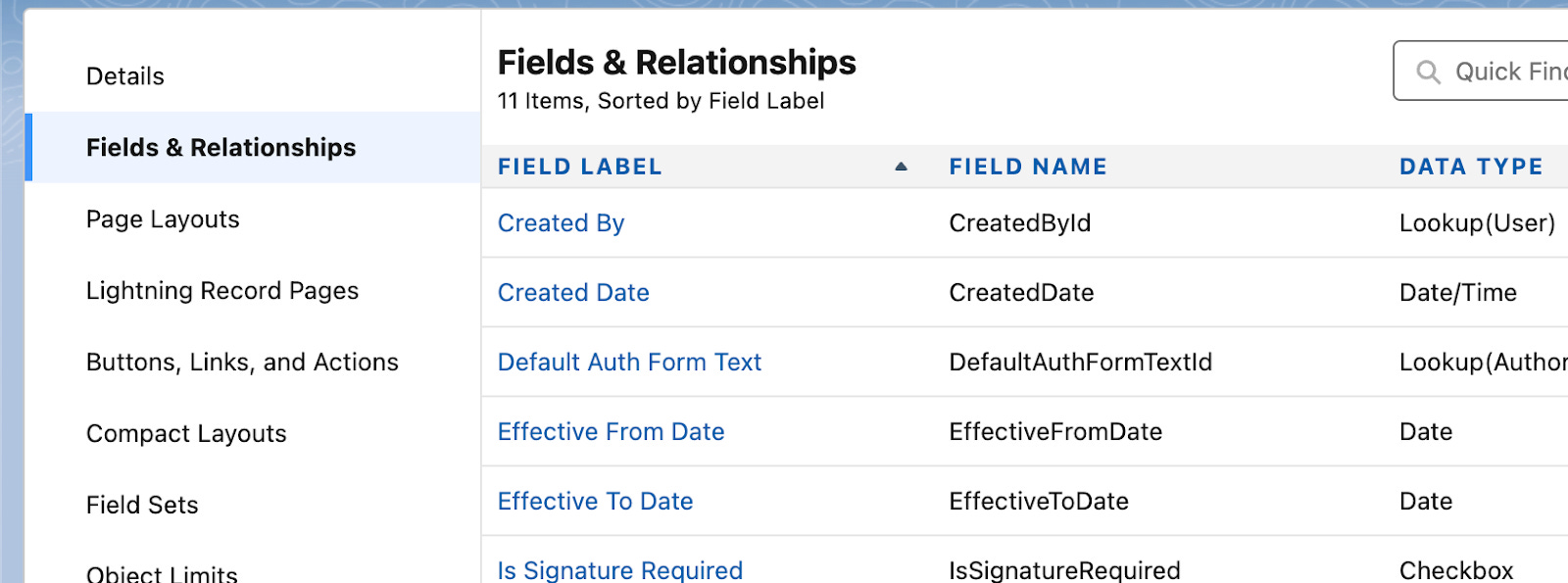
The key item we’re looking for is the Field Name. A best practice is to structure your DBT models so that the column names match the expected Salesforce Field Names. Other important aspects to consider are field permissions and data types. While a reverse ETL tool typically handles field extraction, mapping, and data type validation for you, in this workflow, you’ll need to manage these tasks manually. This offers an opportunity for further iteration and refinement. These steps represent a significant portion of the Airflow work involved in reverse ETL. If you are looking to do this programmatically, then I highly suggest checking out Salesforce’s documentation on this.
Common Challenges and Solutions
Let’s go over some common issues that can arise. One of the first problems you might encounter is when your batch size is too large. If you’re uploading a lot of columns or records, memory constraints on the Airflow worker can come into play. To resolve this, adjust the batch_size parameter in the operator to a smaller value, allowing for smaller incremental pushes to Salesforce.
For datasets that are too large for memory in your airflow worker, you can limit the amount of data returned by your SQL query. Breaking down your dataset into manageable chunks is key. Here's an example implementation:
def generate_sql_queries(start_date, end_date):
# Generate SQL queries based on date range
queries = []
for date in range(start_date, end_date + 1):
queries.append(f"SELECT * FROM your_table WHERE date_column = '{date}'")
return queries
with DAG(
dag_id="dynamic_query_salesforce_bulk_insert",
schedule_interval=None,
start_date=datetime(2024, 1, 1),
) as dag:
generate_queries = PythonOperator(
task_id="generate_queries",
python_callable=generate_sql_queries,
op_kwargs={"start_date": "2024-01-01", "end_date": "2024-12-31"}
)
# Dynamically generate bulk insert tasks
for i, query in enumerate(generate_queries.output):
bulk_insert_task = SalesforceBulkSQLOperator(
task_id=f"bulk_insert_{i}",
sql_conn_id="connid",
sql=query,
# ... other parameters
)
generate_queries >> bulk_insert_taskThis approach solves common issues on the Airflow side by dynamically generating queries and handling large datasets more efficiently.
On the Salesforce side, you can monitor the status of your bulk data loads by navigating to Setup > Bulk Data Load Jobs. Here, you can see the status of your uploads and troubleshoot any issues. Common errors include mismatched data types, insufficient field permissions, or duplicate records. To resolve these, ensure your field mappings, data types, and permissions are all correct before attempting another upload.
Monitoring Bulk Load Jobs in Salesforce
You can locate bulk load jobs in the Setup menu by searching for them. The bulk load job process consists of three main steps: opening a job, loading data into it, and closing it. In this section, you can identify any issues with the uploaded data or determine if Salesforce encountered errors while processing your records.
The most common error you’re likely to encounter, as indicated in the job results, is duplicate data. This usually happens when there are two objects with the same external ID. In such cases, Salesforce will be unable to determine which record to retain, so it will be your responsibility, along with your Salesforce maintainers, to deduplicate the records and ensure that the data is accurate. Check the Salesforce documentation for further reading on this.
Another common issue you'll encounter is a failed job, which can be either silent or explicit, as Salesforce’s behavior can sometimes be inconsistent. These are always interesting to troubleshoot. If you receive a malformed request, it’s usually due to a data type mismatch. Double-check your data types—ensure, for instance, that a boolean value matches a checkbox field in Salesforce. Silent failures, where the Airflow job shows as complete but the bulk operation fails, are trickier. In such cases, reviewing field permissions is a good first step in identifying the problem.
Conclusion
In this article, I aimed to provide the most comprehensive open-source guide for leveraging Airflow and DBT for reverse ETL processes. We delved into the essential requirements for transferring data to Salesforce, highlighting that while it's possible to achieve this without syncing from Salesforce, doing so can complicate the task of ensuring you are working with the correct records.
Implementing a round-trip sync allows you to efficiently update only the records that have changed, streamlining your data management workflow. However, writing the SQL queries for your DBT models falls outside the scope of this guide.
As you move forward, keep in mind the importance of proper field mapping, handling duplicate records, and maintaining data integrity. This journey into reverse ETL with Airflow and DBT is a vital step for data practitioners seeking to enhance their data workflows while utilizing open-source tools effectively. I hope this guide serves as a valuable resource in your data transformation endeavors.
Dan Siegel is a seasoned Data Engineer with extensive experience in developing and optimizing data pipelines and solutions. Holding a Master of Science in Data Science and multiple industry certifications, he specializes in leveraging open-source tools to drive efficient data management practices. Currently, he works as a Senior Data Engineer, where his focus is on modernizing data models and streamlining workflows.
For inquiries, please connect on Linkedin