
I Built a DuckDB Extension for Snowflake (And Learned a Lot Along the Way)
Introducing Snowducks


At Data Council I got to see DuckDB instant SQL. It looked pretty cool, offering real-time query previews and CTE debugging directly within your local environment as you type the SQL. The idea of getting instant feedback on complex SQL is def interesting-not interesting enough to pay for it (looking at you DBT Fusion), but cool enough.
However, my immediate thought was: ‘I don’t know if it’s the best idea for a cloud database (like Snowflake), but I want it.’ A bunch of things immediately came to mind for why it doesn’t actually make sense, but like I said, I want it. Those include dealing with datasets too big for my local machine, network latency, and so on and so forth.
So, with that thought, I decided I’m not getting paid for this anyways, just build what the hell I want.

Why This Project Exists
This project wasn't born out of a gaping market need or a client's urgent request. Instead, it was an exploration driven by pure technical curiosity and a desire to enhance a specific type of data development workflow. And so:
Enhancing Local Development: Could I make the experience work with snowflake locally, and do it probably just as good as fusion?
Leveraging New Tech: DuckLake had just been announced, it’s pretty cool, but I don’t have a use case for it right now.
Deep Dive into DuckDB Internals: I thought this was going to be a simple UDF. I didn’t realize I’d build it and get it working in like an hour with python and then have to dick around with Cursor and use it to help me write some C++.
This is a lesson in you should probably read documentation before diving headfirst into a complex build. But I think on the flip side, probably a good reason not to. Had I known what it would take, I’d have probably spent 10 minutes researching it and fucked off.
What I Actually Built
Introducing SnowDucks – a DuckDB extension designed to cache Snowflake queries for instant SQL execution.
Here's a quick rundown of what it does:
Connects to Snowflake using the ADBC driver.
Checks for cached data locally, leveraging a query hash for identification.
Returns data instantly if it's cached and fresh.
Pulls fresh data from Snowflake with automatic row limits if not cached or stale.
Stores everything in Parquet format using DuckLake.
Works seamlessly with DuckDB's Instant SQL features.
The Technical Journey (Or: How I Made Everything Harder Than It Needed to Be)
Phase 1: The Python Prototype (Because I Didn't Do Research)
I started with Python because... well, that’s what I know best and I didn't do any research. I just started coding. This is where the read documentation first lesson began to unfold.
I managed to build a working prototype that could connect to snowflake, cache data locally, and returns the data all in CLI. It took me like an hour or 2 and that was it.
But then I was like wait how do I import this in the UI. You can’t. FML.
Phase 2: The C++ Rewrite (Because Extensions Are Hard)
DuckDB extensions need to be written in C++. This is where things got really interesting.
I quickly had to learn (with some cursor help):
DuckDB's extension API.
How to write table functions in C++.
Memory management in C++.
How to integrate with DuckDB's intricate type system.
The extension itself needed to:
Generate unique cache table names based on query hashes. (well I didn’t have to. I built the caching steps because I wanted to)
Handle the bind phase (create an idempotent process of checking the cache, and ALWAYS returning the schema if it is cached or not cached).
Manage the execution phase (if cached, just run, if not retrieve the data).
Integrate with DuckLake for metadata storage.
Phase 3: The Architectural Decisions
I made some... interesting architectural choices along the way:
PostgreSQL for Metadata: I initially tried using DuckDB as the catalog for DuckLake, but ran into issues with concurrent connections. So, I switched to PostgreSQL. This actually worked out better in the long run, as it properly separated concerns.
Query Hashing: Each unique SQL query gets a SHA256 hash, and the first 16 characters of that hash become the table name. This ensures consistent caching across sessions.
Row Limits: By default, it limits queries to 1000 rows unless you explicitly allow unlimited egress-because I'm not trying to accidentally bankrupt anyone.
DuckLake Integration: The extension uses DuckLake for the actual data storage, which means you get all the benefits of DuckLake's columnar storage and robust metadata management.
Python Dependency: I know python. C++ isn't really something I’m using heavily. I also already had the ADBC drivers in my venv, and my existing code already worked. Rather than really rewrite it into C++, I just went with what I was comfortable with, which was using the C++ code to call the python code. Kinda gross, I already know.
The "Why Would You Do This?" Questions
I posted this on reddit immediately after I finished. Despite the fact that I said 3 times, because I wanted to…these are the questions that kept coming up:
"Snowflake already caches query results for 24 hours!"
Yes, but this isn't about Snowflake's internal cache. It's about the DuckDB Instant SQL. Quick fast queries that change as you type the SQL. If you keep querying Snowflake, it defeats the purpose.
"Why not just use the ADBC driver directly?"
Instant SQL…
"This doesn't save Snowflake credits!"‘
It's not primarily meant to? Its purpose is to provide a local development experience with instant feedback, decoupling your iteration speed from live Snowflake query execution and potentially reducing unnecessary cloud compute for exploratory work.
"Why not use S3 with Iceberg tables?"
Because I wanted to use DuckLake. For reasons.
Lessons learned
1. Read Documentation First (But Also: Just Start Coding)
While I advocate for reading documentation first as a crucial lesson, here's the rub: when you have the momentum to build something, sometimes the best thing to do is just start coding.
If I had read the DuckDB documentation first and immediately discovered that I needed to write a C++ extension after building the Python prototype, I likely would have stopped. The perceived complexity would have been too much and I’d be like F it. But because I already had a working Python version, I was invested. I had momentum. I had something tangible that worked, and I wanted to make it actually work.
TLDR: Not knowing the full scope of a challenge can sometimes be helpful.
2. Extensions vs. UDFs Are Very Different
UDFs are relatively simple. Extensions, on the other hand, are complex. They require a deeper understanding of DuckDB's internal architecture, memory management, and intricate type system.
3. ADBC Drivers are Cool
The ADBC driver is powerful, but it has its quirks. Learning to work with it took some time, but being able to use ADBC directly can be helpful in many other contexts.
4. DuckLake Is Also Pretty Cool
I ended up using DuckLake for the actual data storage, and I was impressed. My poor decision to use C++ to call the python actually triggered a second connection to the database. When I tried to do that, it was locked because the primary process was holding the file open.
TLDR: I accidentally built it correctly if I wanted to scale this to run off of S3 with multiple users on the same DuckLake.
5. "Because I Felt Like It" Is a Valid Reason
Not every project needs to solve a business problem or fill a market gap. I had posted this to Reddit, and everyone was like wtf are you trying to solve here?
The Workflow vs. The Implementation
Let's be honest: the implementation itself is "meh." It's a personal project, built in my spare time, and it shows. But let's talk about the actual workflow, because I think that I ended up with the right workflow if I really wanted to build this
The Workflow I Built
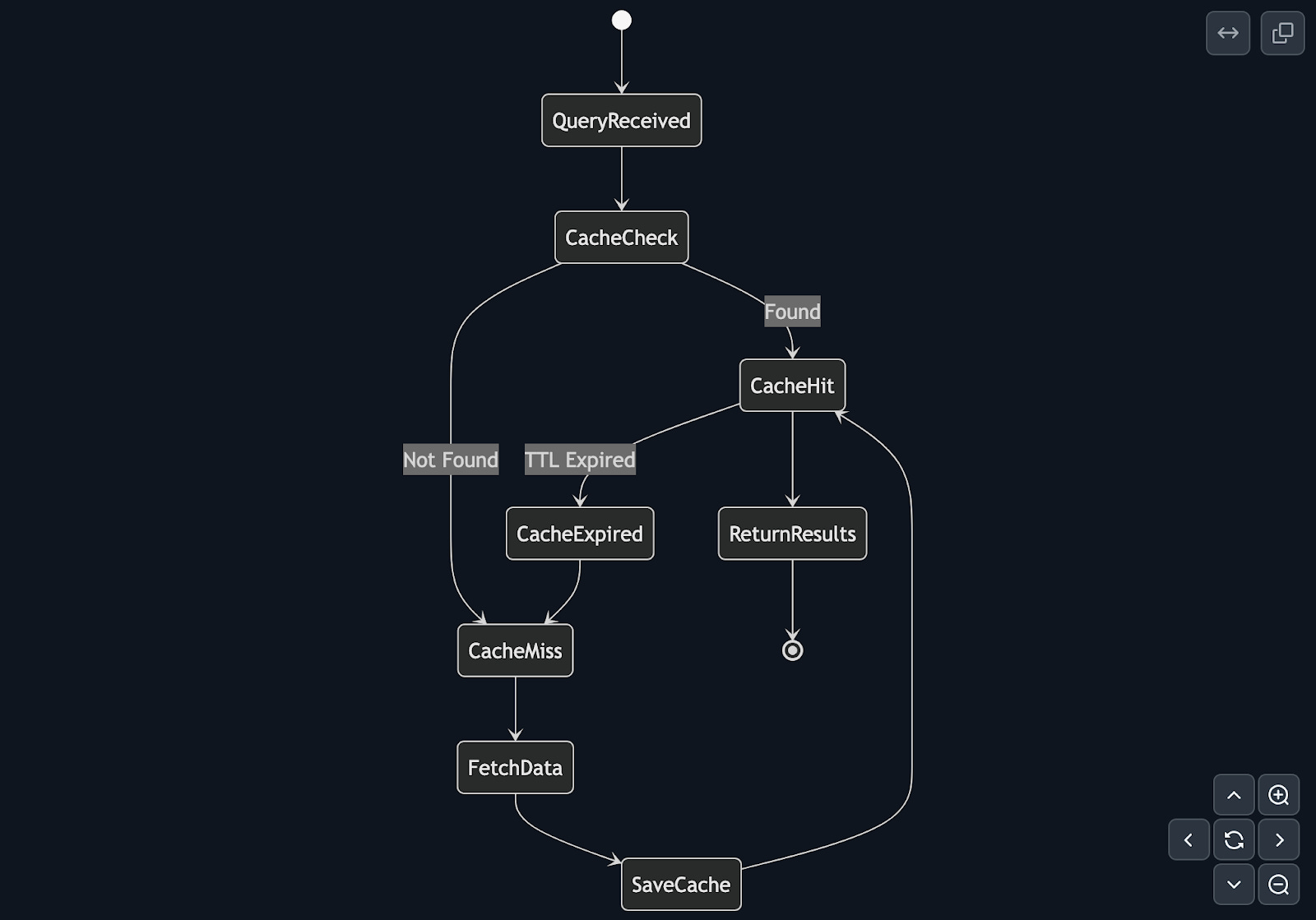
Write a SQL query against your Snowflake data in your DuckDB UI. If the data is already cached, results appear immediately, allowing you to begin exploring and manipulating the data. If it’s not, get the data, store it, and then return it.
Under the hood, when you submit a query, there are two standard parts to query execution, the bind and execute phases. The extension's bind phase needs to be idempotent by definition. It always returns the schema. So it checks whether the data for that specific query is already cached locally. If it is, return schema, if not, fetch only the schema from Snowflake. Fun fact: instant SQL always needs its schema defined in bind. In the execute phase, if the data was found locally, pull from cache. If not cached, then retrieve-store-return.
TLDR: Bind = always return just the schema, Execution = always return the data
Why the Workflow Matters More Than the Code
When you can write a complex query and get instant feedback, it changes how you approach data exploration. When you can iterate on queries without worrying about costs, it transforms your problem-solving process. When you can use DuckDB's powerful features directly against your Snowflake data, it opens up entirely new possibilities.
TLDR: An idempotent bind phase, and a very quick execution phase
The Current State
The project currently works on my machine. This includes a C++ DuckDB extension handling the execution, complemented by a Python UDF for a more simple interface. It integrates with DuckLake, has automatic query caching with hash-based invalidation, and has built-in row limits. I'm not sure if I'll continue actively developing it, but it works flawlessly on my machine, and that, in itself, is pretty cool (at least to me).